通过火车采集器官网的faq为例来说明采集器采集的原理和过程。 本例以 http://faq.locoy.com […]
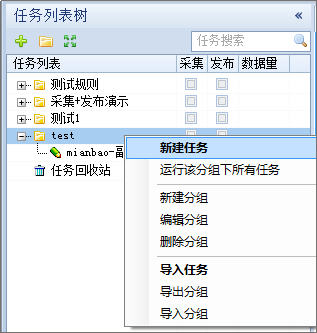
通过火车采集器官网的faq为例来说明采集器采集的原理和过程。 本例以 http://faq.locoy.com […]

火车采集器V9.7数据同步功能的使用详解教程 数据同步功能是将当前采集器中存在的任务保存到云端,以便在需要的时 […]

火车头浏览器打开软件时,软件无反应或者提示已停止工作,错误异常代码为,错误提示示例如下: 火车头浏览器错误解决 […]

火车采集器V9.7压缩优化任务数据库功能说明,有用户反映原来V8版的压缩优化任务数据库功能在V9版上找不到,其 […]
[系统时间戳:时间] :把时间转换成时间戳 时间格式如:2015-04-04 只能这种格 […]

火车浏览器之数据库的使用教程和注意事项,在执行SQL语句时首先要添加数据库配置 执行SQL操作
火车采集器支持php插件对数据进行处理。php插件的原理是通过调用命令行的php.exe,对数据进行处理。 v […]
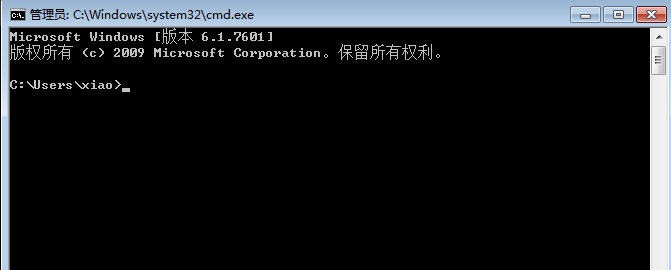
开始–运行中 输入 cmd 进入界面 再输入 […]
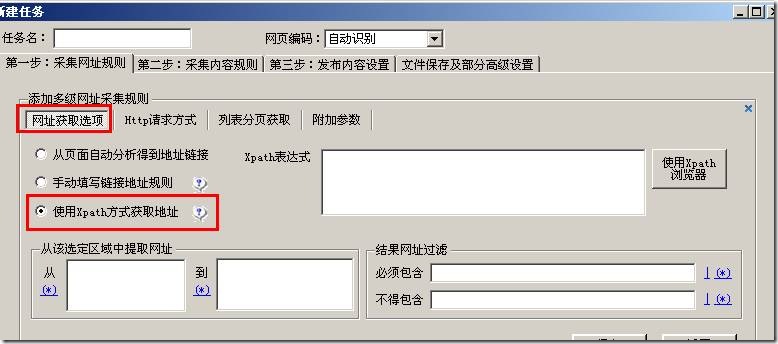
Xpath可视化提取功能旨在做到用户所见即所得,仅仅通过鼠标点击进行规则配置。但是此功能不适合大部分网站。 1 […]
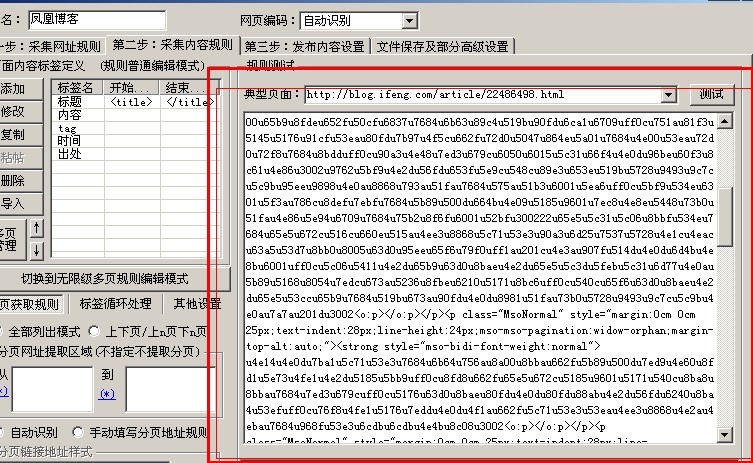
火车采集器里面的字符编码解码功能介绍,有时候采集的结果被转义了,那么如何获得我们要的结果呢?? 比如下图采集的 […]
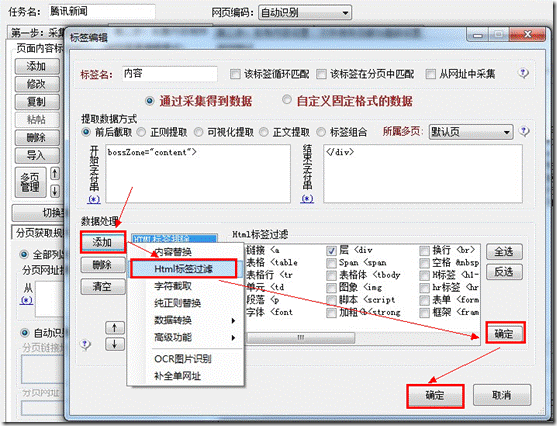
我们在采集的时候会采集到一些代码,那么我们就可以使用html标签过滤功能,可以很方便的将一些代码过滤掉。 1、 […]
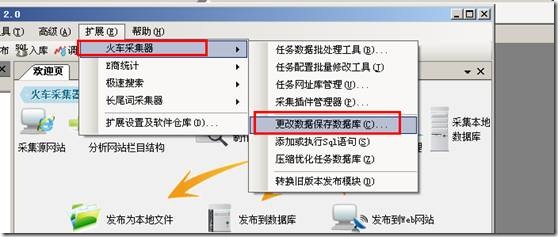
如何修改火车采集器V7.6本地保存数据库修改,这里说的数据库是采集器存放采集数据的地方,只需给采集器选择一个数 […]
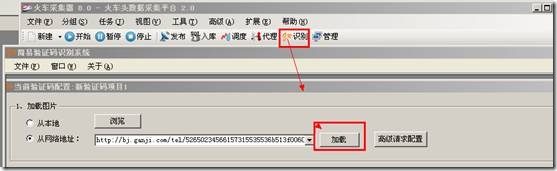
火车采集器7.6之ORC识别图片文字使用教程,Orc识别功能,是可以把一些简单的图片信息识别成文字信息的,网站 […]
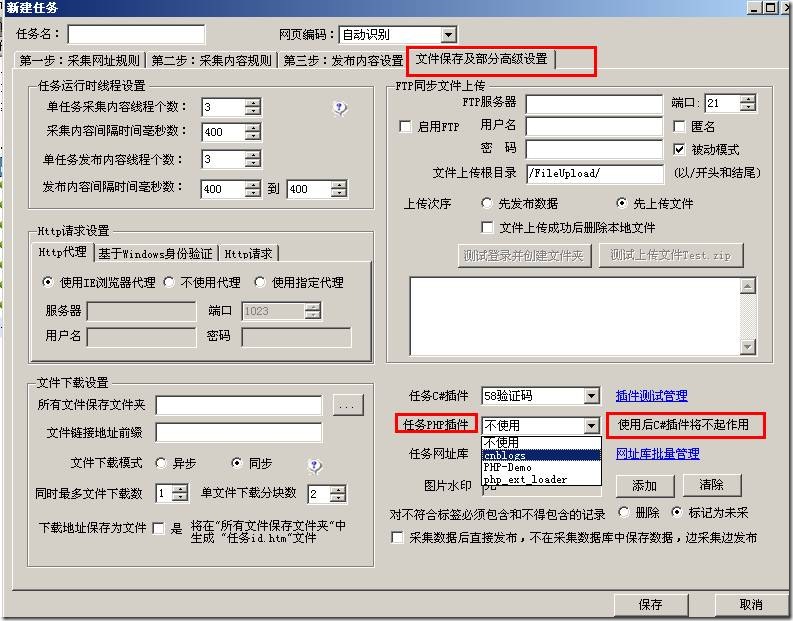
火车采集器7.6如何调用php外部编程插件使用教程,如果你是程序员或者对php有一定的了解,看了说明文档还是不 […]
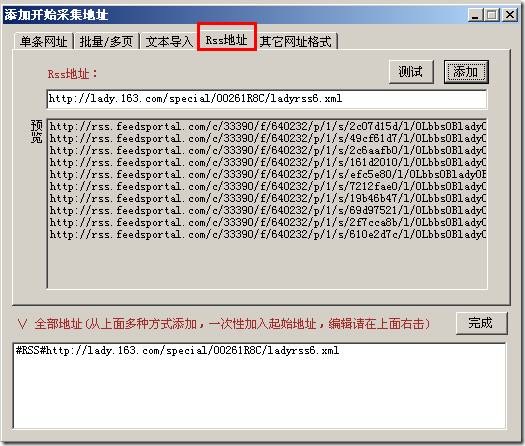
火车采集器7.6之如何添加起始网址之RSS地址采集功能,只要给采集器提供RSS地址,采集器就能把内容页地址提取 […]
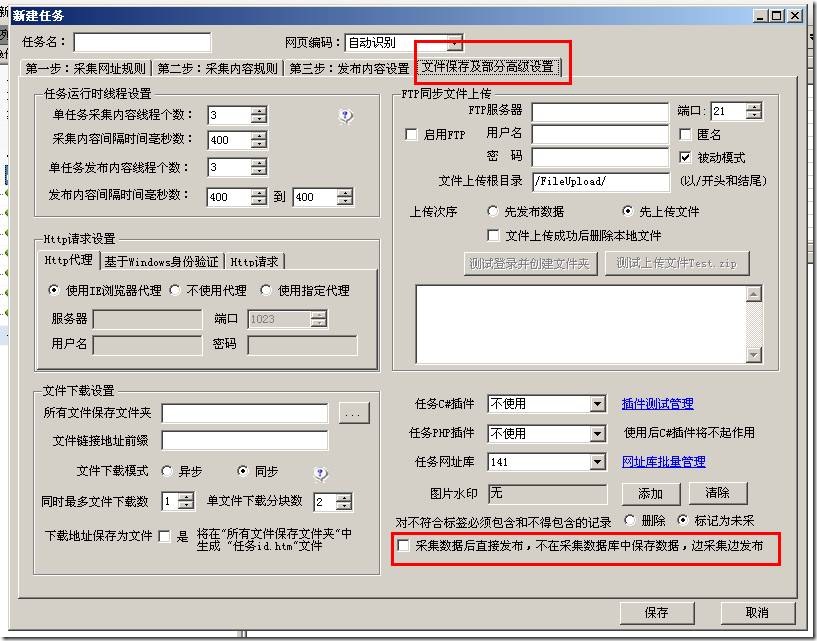
默认情况下,火车采集器会把采集的数据先保存到自己的数据库,然后根据用户设置的发布配置,再从数据库里面读出数据通 […]
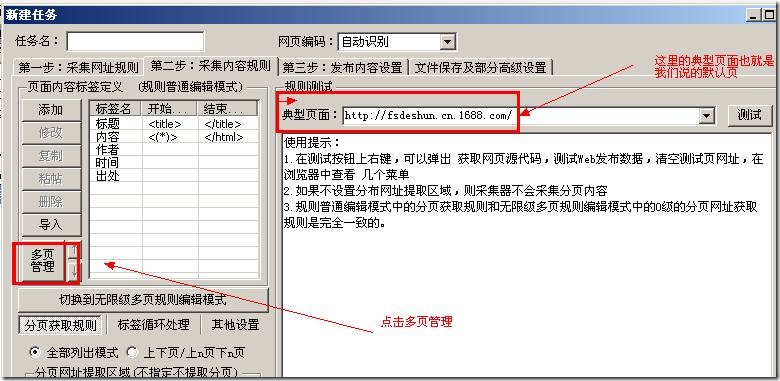
火车采集器之多页采集网址设置教程,什么是默认页?什么是多页?假如我们通过采集器采集到了最终内容也地址是http […]
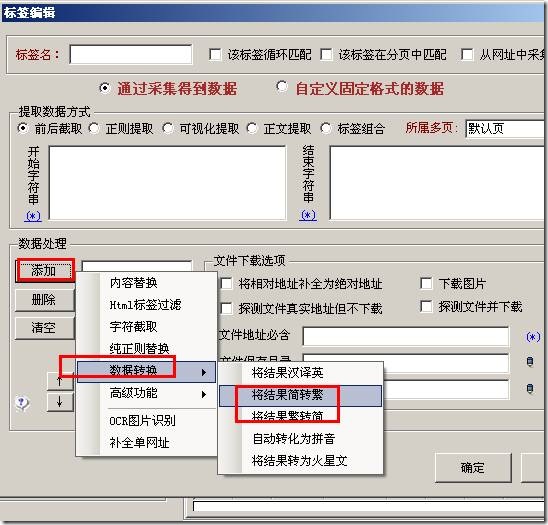
火车采集器之简体繁体互转功能使用教程,简体繁体互转功能如下图:
 中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
 英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
 人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
 英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
 英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
 国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
 英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
 英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
 多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
 英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
 英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
 英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
 英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
 全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
 英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00
英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00




