火车采集器之多页采集网址设置教程,什么是默认页?什么是多页?假如我们通过采集器采集到了最终内容也地址是http://fsdeshun.cn.1688.com/,然后我们还想点击导航栏上面的“联系方式”进入到联系页地址
http://fsdeshun.cn.1688.com/page/contactinfo.htm来继续采集信息。
那么本例的http://fsdeshun.cn.1688.com/在采集器里面就叫做默认页,而地址http://fsdeshun.cn.1688.com/page/contactinfo.htm ,是通过http://fsdeshun.cn.1688.com/获取到
的,那么这个地址 相对与地址http://fsdeshun.cn.1688.com/就叫做多页。
明白了多页和默认页的定义,下面我们来说明写如果从默认页获取到多页。
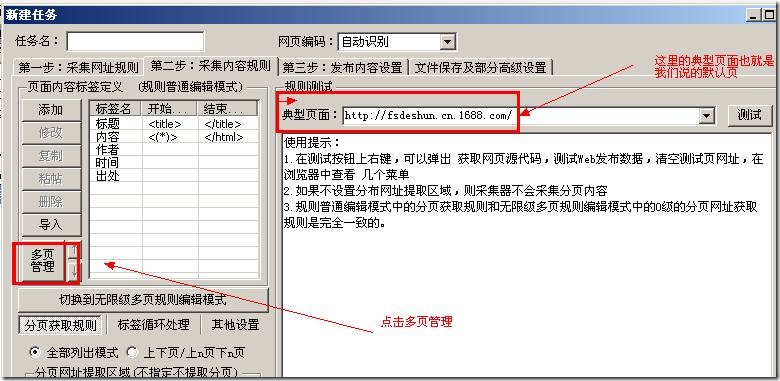
在规则的第二步:采集内容规则,点击“多页管理”按钮,如下图

打开后看到的界面如下图:

上图看到或者地址的方式有两种方式:1,依据规则对默认页地址替换生成地址;2,在默认页源代码内采集得到地址
1,根据规则对默认页地址替换生成地址:也就是默认页和多页地址上面有相同的地方,通过简单的替换就可以变成多页地址。
2,在默认页源代码内采集得到地址:也就是多页的地址在默认页的页面源代码里面。
现在就用采集阿里巴巴公司信息为例来说明下这两种方式如何获取多页。
依据规则对默认页地址替换生成地址
比较默认页“http://fsdeshun.cn.1688.com/”和多页地址:“http://fsdeshun.cn.1688.com/page/contactinfo.htm”之间的共同点,在默认页后面加上“page/contactinfo.htm”就是我们的多页地址了。
写到采集器里面如下图:

上图我们把需要的部分用(.*)代替,这里是用正则替代需要的部分,表示方式很多种,大家记住我这种(.*),是万能的,如果看不懂是什么,那么也不需要纠结了,就记住好了。
下面的替换为是通过$1,$2…$数字来按照顺序对应上面(.*)表示的部分。这里其实用一个(.*)就可以表示了,我这里特意多用了几个,来说明对应关系的。
我们设置好了,把默认页写好然后点击右侧的“测试”按钮,看下测试结果中已经正确获取到我们联系页的地址了,正确后,就可以点击保存了。
这种方式如果默认页地址中出现问号“?”如,那么问号前面一定要加反斜杠写成“\?”,切记切记!!!!!
在默认页源代码内采集得到地址
我们打开默认页http://fsdeshun.cn.1688.com/查看页面源代码,可以发现我们要的多页地址就在页面源代码里面如下图:

我们在采集器里的设置如下:

和设置采集规则一样,正则匹配内容里面我们把需要的部分用[参数]代替,可以使用多个[参数],与后面的组合结果中的[参数1][参数2]....[参数n],按照顺序一一对应的。
同样我们要测试下获取的结果是不是正确的,如果正确那么就点击保存,在写规则里面使用。
规则设置说明我们如果要采集默认页的数据就根据默认页的页面源代码来设置规则如下图:

我们采集多页的信息就根据多页的页面源代码来设置采集规则如下图:

所属多页这里选择的是对应多页的名称!!!!!一定不要忘记了
看下采集效果:















