Xpath可视化提取功能旨在做到用户所见即所得,仅仅通过鼠标点击进行规则配置。但是此功能不适合大部分网站。
1, 使用Xpath方式获取地址
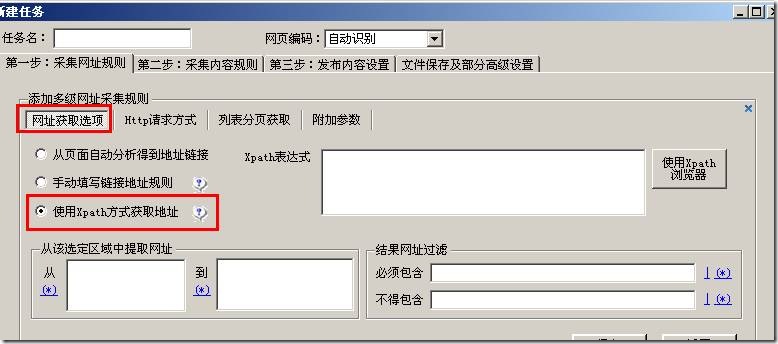
在第一步,我们通过Xpath方式来获取内容页地址

如上图,选择“使用Xpath方式获取地址”,选中后右侧有个“使用Xpath浏览器”按钮,点击下。

在地址栏里面输入列表页地址,然后点击右侧绿色的按钮,使用这个浏览器来访问我们要采集的列表页地址。

点击上图的那个红色标志的箭头,然后鼠标放到浏览器内就有个淡蓝色的框,表示被选中的部分,那么要选中那一部分才行呢?看下图

当淡蓝色框选中的部分,在左下角能显示出文章地址,就说明这个淡蓝色的框选择的就合适,然后鼠标在选中的框那里轻轻点击下,不需要点击访问内容页,只需要点击下就可以。
这里看到点击后,看下图有个变化:

和上图这个地方不一样,变成初始状态了,下面要把上述操作再做一遍,也是首先点击这个,再选中标题。要注意。
然后我们再随便找个标题按照上面的步骤再做一遍,这一步非常的重要,必须要重复做2遍。

然后如上图点击测试,如果测试结果正确,就点击确定按钮

Xpath表达式就自动填写好了。
如果测试提示结果如下图:

上面说了这个方式不适合所有的网站,如果有上图提示,说明没有办法使用这个方式来采集,目前也没有办法解决,请你换别的方式采集。
2,使用Xpath获取内容
新建标签,提前数据方式选择,“可视化提取”选项 ,如下图

同样点击“通过XPath浏览器获取” 按钮。
和上面获取地址一样的,输入地址,访问要采集的地址,如下图:

然后点击图标开始选择,我们这里用获取标题为例说明。

淡蓝色框选中标题,轻轻点击鼠标,然后测试看下是否正确。如果正确点击确定按钮。这个不像采集地址的时候需要做2遍。如果测试弹出

这个就是说明这个页面不能使用这个方式获取。
点击确定后如下图:

获取这个标题的表达式就自动填写在这里了。我们测试下结果

结果是正确的。别的其他信息都可以通过这个方式获取。
有个节点属性如下图:

这个是也是专业术语,大家可以查资料了解下,一般选中InnerHtml和 InnerText 就可以获取到文字信息了,需要了解更多,自行查找资料。
选择“Href”是获取链接地址,选择“OuterHtml”是获取文字和包含的html代码。大家如果不明白可以实际操作测下结果。














