全局敏感词替换&近义词替换,功能可以把要替换的词写成一个TXT,遇到要替换的标签,只需要选择下就可以了,一次设 […]

全局敏感词替换&近义词替换,功能可以把要替换的词写成一个TXT,遇到要替换的标签,只需要选择下就可以了,一次设 […]
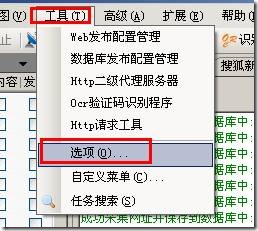
火车采集器之任务运行日志使用方法 1,首先开启日志功能 默认是不开启的,也就是不记录采集器的运行情况,如下图 […]

火车采集器之任意格式文件下载功能使用方法解说,如下图: 编辑标签界面,文件下载选项,勾选探测文件并下载,会把采 […]
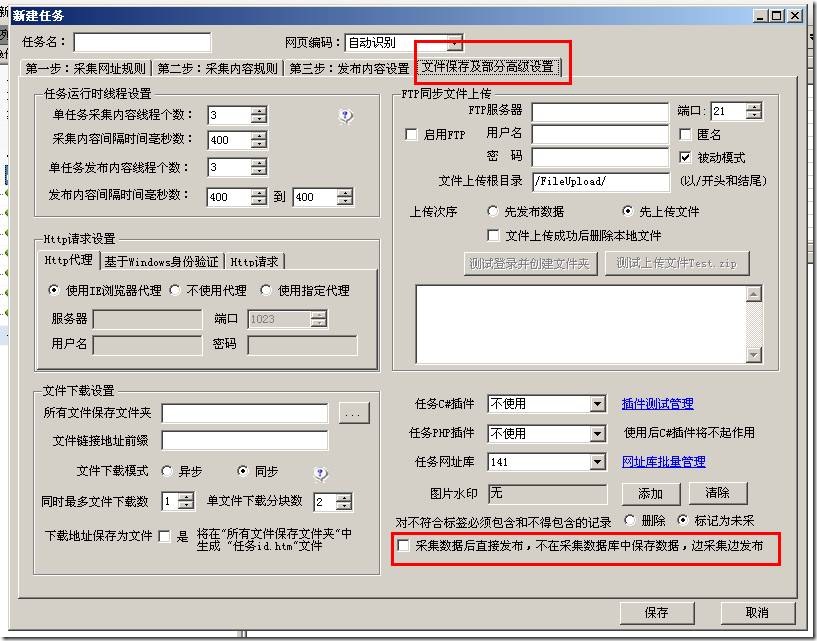
默认情况下,火车采集器会把采集的数据先保存到自己的数据库,然后根据用户设置的发布配置,再从数据库里面读出数据通 […]
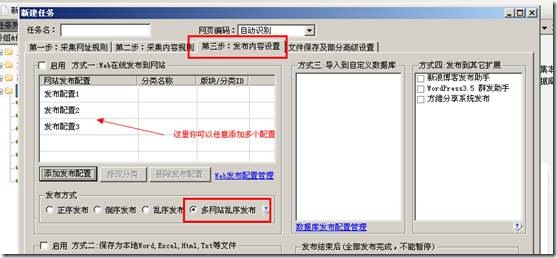
火车采集器之多网站站群式web发布的设置方法,假如你需要把一个采集规则采集到的信息同时发布到多个网站或者一个网 […]
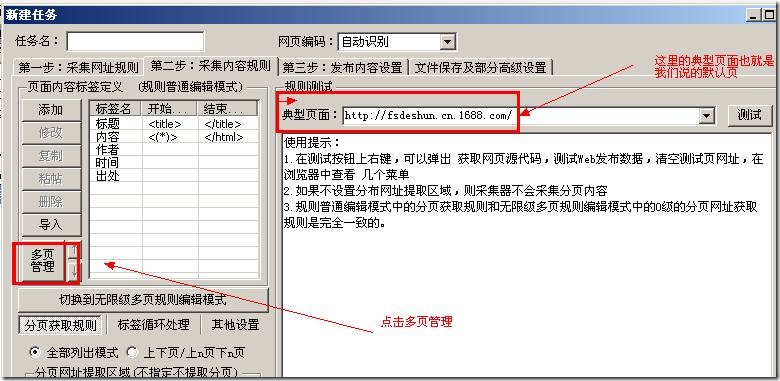
火车采集器之多页采集网址设置教程,什么是默认页?什么是多页?假如我们通过采集器采集到了最终内容也地址是http […]
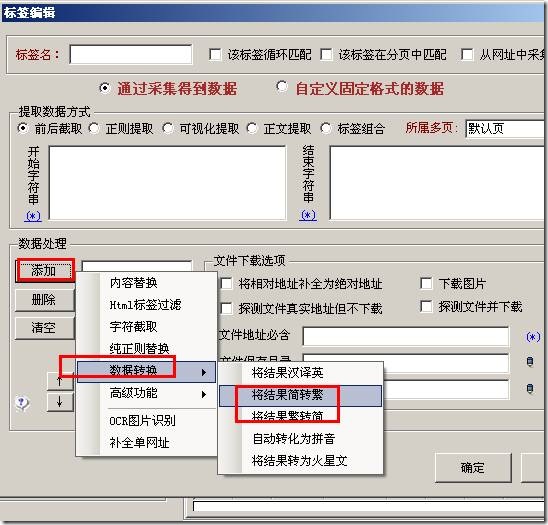
火车采集器之简体繁体互转功能使用教程,简体繁体互转功能如下图:
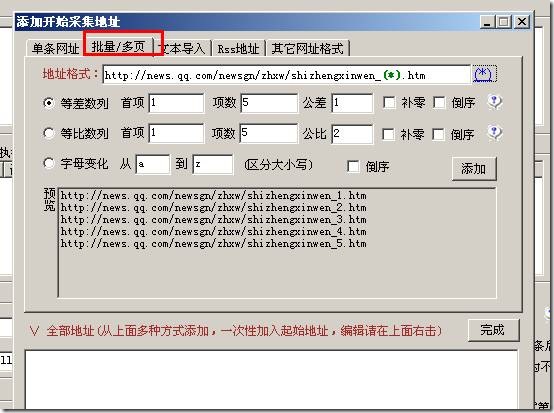
火车采集器之列表页分页采集获取功能使用方法,对于设置列表分页,下图设置是最常见也是最常用的。 现在教大家另外一 […]

列表页附加参数获取功能,是在采集内容页地址的时候,通过设置采集规则,获得的值,也就是获取列表页的值,该值将被循 […]
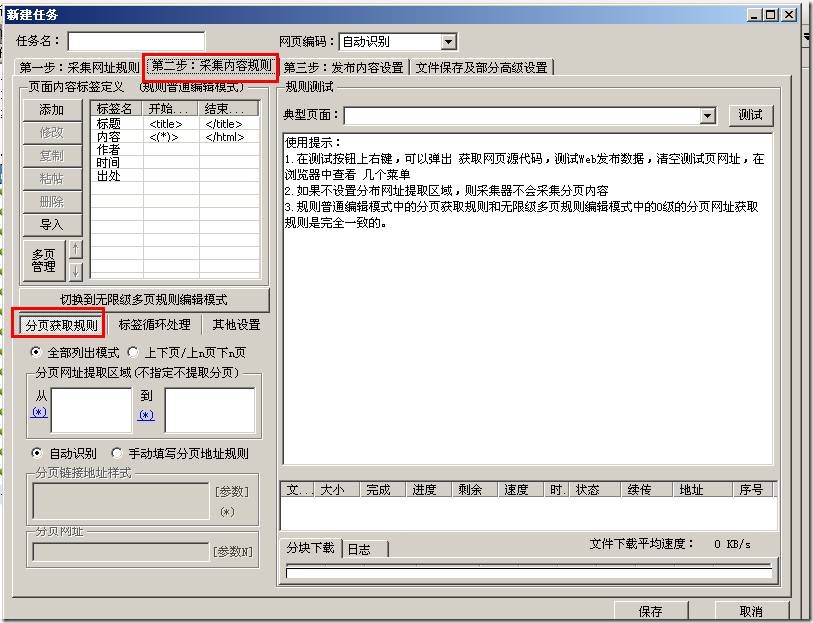
火车采集器之内容分页采集使用教程,采集文章的时候,难免遇到文章有分页,本教程讲解下内容分页的采集。 在规则的第 […]

这里只是略说重点,需要更多更多深入的了解火车头采集软件请看教学视频。 火车头采集器使用视频教程(入门) htt […]

火车数据采集平台是一款通用型数据采集程序框架。它包含了数据采集最常用的计划任务,数据发布,正文识别、OCR图形图像识别,采集入库等模块,可以支持其它采集软件快速稳定在平台上使用。火车采集器平台定义了统一的接口规范并提供了大量的api,用户可以很方便的开发自己的应用并在该平台上运行,可以减少开发上时间和成本。目前平台上有官方自带火车采集器。
如何利用火车采集软件采集58招聘信息 今天我们要讲解的内容是:“如何利用火车采集器采集58招聘信息”。 […]
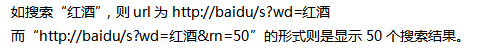
如何使用火车采集器V9.7采集百度搜索关键词教程,当我们在进行网站优化以及内容更新的时候会发现,大批量更新文章是需要很多关键词。而自己手动统计的关键词是远远不够使用的,因此我们会从其他同类型的网站中获取关键词,这时就要用到网页抓取工具,进行关键词的高效采集,也能大大减少时间和人力成本。

案例网站:http://www.mornsun.cn/html/selection.html 采集内容:如下图 网站分析:

通过火车采集器官网的faq为例来说明采集器采集的原理和过程。 本例以 http://faq.locoy.com/qc-12.html 演示地址,以火车采集器V9为工具进行示例说明。

抓取网页数据的工具火车采集器V9将标签组合功能放在了数据获取方式选项中,即可以通过标签组合来获取标签数据,下面讲解一下该功能如何使用。学习之前需要注意以下几种情况:
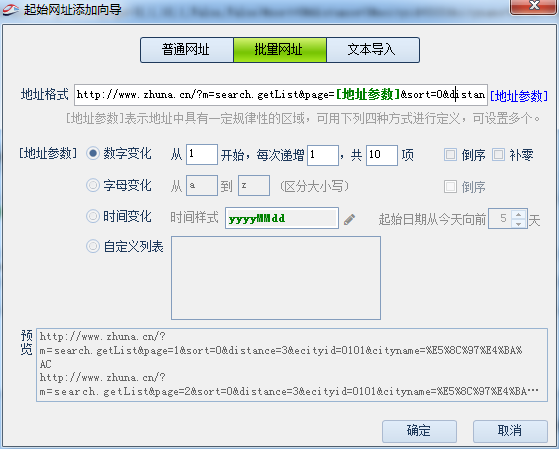
今天为大家讲解网址拼接,我们经常在采集的时候,发现源码中并没有完全的网址或完全的网站不好制定规则,那就可以使用网址拼接功能,今天以酒店信息采集案例讲解网址拼接功能。
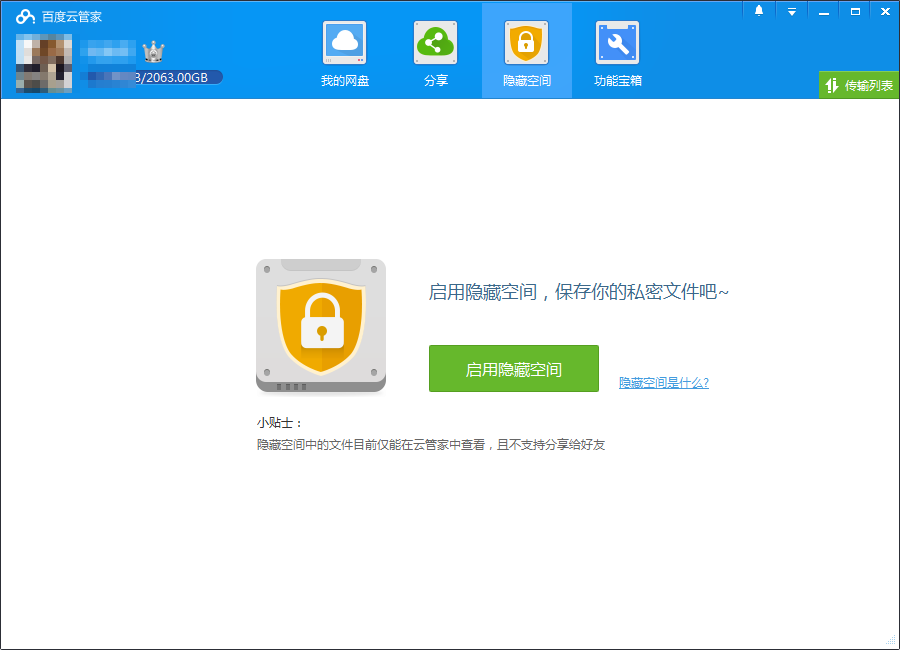
以前我发过不少可以不限速下载百度网盘文件的工具,但大都失效了,所以今天再来整理一下目前能用的工具分享给大家。 […]
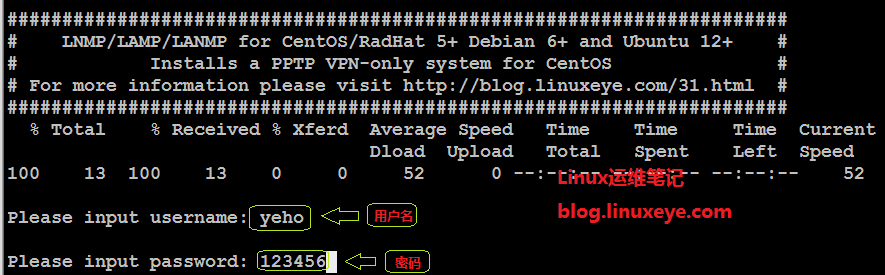
1, 这个脚本可以单独使用,直接复制或下载执行即可,不用依赖安装包的其它脚本。 CentOS 6、7下pptp […]
本采集功能以火车采集器V8.6为基础制作而成,绿色无需安装。运行LocoySpider.exe后点击登陆就行了 […]
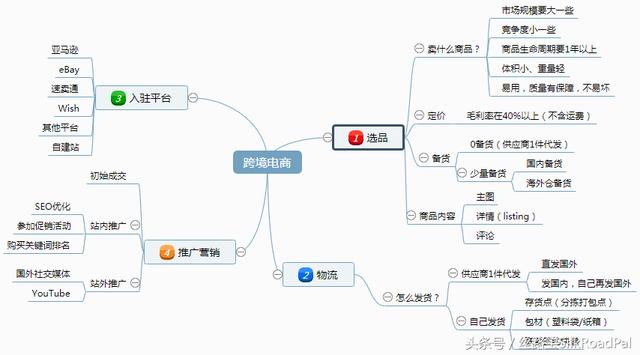
目前跨境电商发展前景很好,很多人都想做跨境电商,新手如何开展跨境电商? 跨境电商开展步骤 一、选品 选品对于跨 […]
修改添加广告,老手最好的方法是直接修改模板。对于要修改到php文件的时候需要使用到代码编辑软件! […]
”塔克主题面板Theme Options“英汉对照图,买主题的就扫一下眼吧,应该能很快上手,不是太复杂这东西。 […]
一、国外Lead里面常说的Offer指的是什么? 答:一般来说Offer就是指联盟里面推广的任务,这个Offe […]
申请国外广告联盟需要注意一些细节和技巧才能提高成功率。如果申请国外联盟账号不成功的话,我们想要操作lead项目 […]

一、安装WP-AutoPost 和安装其他WordPress插件一样,直接上传到插件目录,激活即可使用,无需再 […]

所有的主题为整站源码,直接上传导入就可以使用。如果你有感兴趣购买可按以下方式联系: 联系QQ: 或者加微信好友 […]

下载压缩包到本地,解压缩,双击解开的文件夹中的readme.html文件,即可查看WordPress的介绍、安 […]

Visual Composer 是一个强大的可视化编辑器,与Wordpress配套使用,简直是非程序员的福音, […]

有时候,我们可以会更换域名,或者更换图库地址,那我们就需要批量修改相关的链接地址,倡萌一直都是直接在phpMy […]
解决方法一:安装禁止谷歌插件。 为什么wordpress的打开速度非常慢,有时候需要10几秒钟才能打开,通过F […]
 中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
 英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
 人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
 英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
 英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
 国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
 英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
 英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
 多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
 英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
 英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
 英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
 英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
 全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
 英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00
英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00




