抓取网页数据的工具火车采集器V9将标签组合功能放在了数据获取方式选项中,即可以通过标签组合来获取标签数据,下面讲解一下该功能如何使用。学习之前需要注意以下几种情况:
1.标签组合是组合文件下载前的内容
有的朋友发现,a标签中下载了某个文件,原始地址是aaa,下载后或是探测的地址为bbb,那么,如果您在b标签中组合使用a标签,a标签的值是aaa.为何使用这种处理方法,是因为文件下载是在标签组合之后进行的。如何达到标签内容是文件下载完后的结果呢?可以新建一个标签,选“自定义固定格式数据”,将您标签组合的内容放进去。这里的替换会在文件下载后执行。
2.内容页标签循环采集并添加为新记录
如果组合的两个标签都是内容页标签,这两个标签在组合时,会按循环数最大的记录产生新的同样数目的循环记录。如果某个标签的循环数较少,则新产生的标签中该标签的值为空。例如标签a,b组合生成标签c。a的循环数是5,b的循环数是3,则会生成5个c,其中,前3个标签的值分别是a,b一一对应的。最后两个值中,b的值为空。比如我们假设a的值是11、22、33、44、55,而b的值为aa、bb、cc,那么c是由[标签:a][标签:b]组合的,则产生的c的值为11aa、22bb、33cc、44、55,后面两个b值为空。
3.列表页标签和内容页标签组合
如果两个标签中一个是内容页,一个是列表页,则内容页是会参加第2条中的循环处理,在这个过程中列表页先当作一个字符串处理。合并完成后,程序会再进行数据处理操作。最后,组合标签中的列表页标签内容将被替换成实际的值。组合后的结果中,可以再提取下载。比如内容页a和列表页b组合生成c,其中a的值为11、22、33,b的值为bb,那么,c第一次组合结果是11[标签:b]、22[标签:b]、33[标签:b],然后进行数据处理:如果b的值是bb,那么最后的结果就是11bb、22bb、33bb。
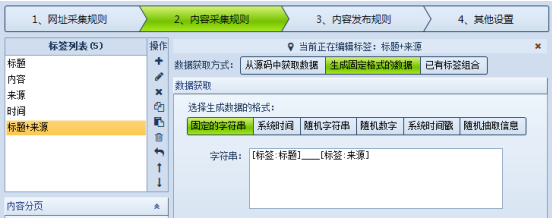
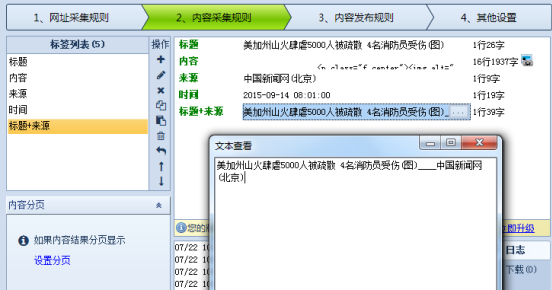
下面来实际操作下,已有标签的组合操作示例如下: