抓取网页数据的工具火车采集器V9将标签组合功能放在了数据获取方式选项中,即可以通过标签组合来获取标签数据,下面 […]
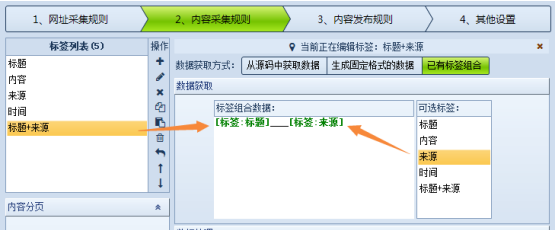
抓取网页数据的工具火车采集器V9将标签组合功能放在了数据获取方式选项中,即可以通过标签组合来获取标签数据,下面 […]
通过火车采集器官网的faq为例来说明采集器采集的原理和过程。 本例以 http://faq.locoy.com […]

案例网站:http://www.mornsun.cn/html/selection.html 采集内容:如下图 […]
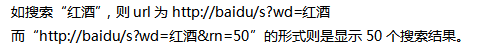
如何使用火车采集器V9.7采集百度搜索关键词教程,当我们在进行网站优化以及内容更新的时候会发现,大批量更新文章 […]

火车采集器V9.7数据同步功能的使用详解教程 数据同步功能是将当前采集器中存在的任务保存到云端,以便在需要的时 […]

火车采集器V9.7压缩优化任务数据库功能说明,有用户反映原来V8版的压缩优化任务数据库功能在V9版上找不到,其 […]
火车采集器V9.7加载CSV模板出错添加了重复的表头的解决方法 出现这个的问题是因为CSV模板没有正确编辑 方 […]

火车采集器V9.7自动获取二级代理的代理服务功能使用说明 1.点击开始菜单上的http二级代理服务器进入设置界 […]
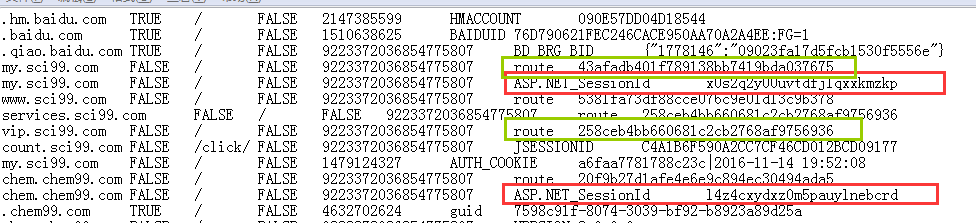
火车浏览器导出的cookie是所有打开页面的cookie,而火车采集器在调用该cookie时,若有多个相同的k […]
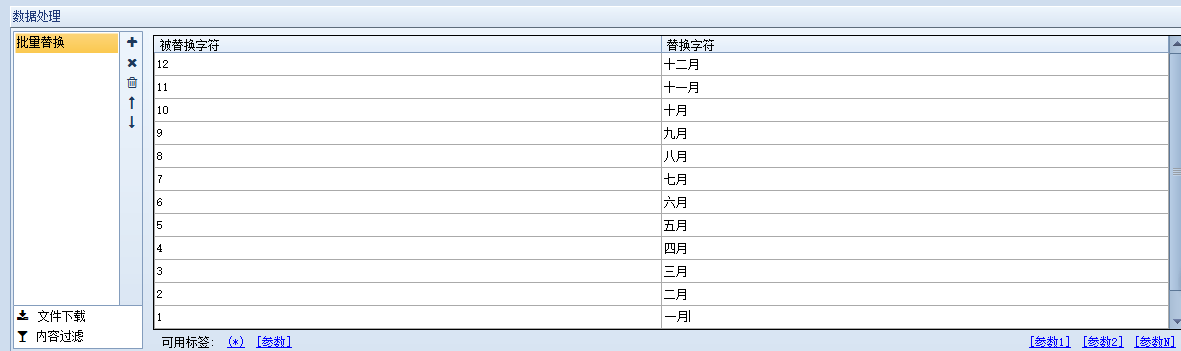
火车采集器V9.7批量内容替换功能使用方法,比如我们想把采集到的时间改成汉字形式,如我们想要将月份替换成汉字, […]
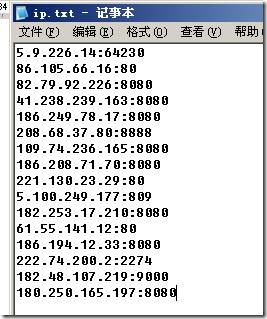
在我们采集过程中,如果遇到对方网站限制了你的ip访问,就可以通过二级代理服务器的功能,来实现更换ip。 1, […]
[系统时间戳:时间] :把时间转换成时间戳 时间格式如:2015-04-04 只能这种格 […]

火车采集器V9.7批量导入Http二级代理设置教程,在使用Http二级代理的时候,经常会使用到批量导入这个功能 […]
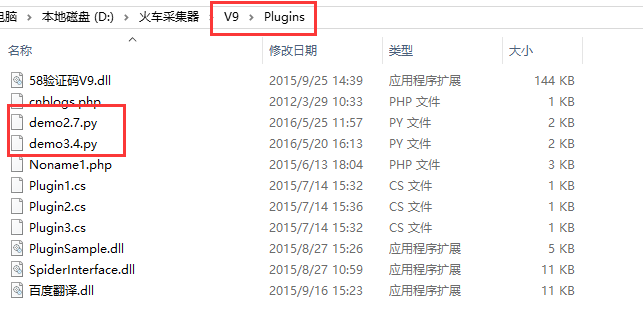
火车采集器V9.7版本及以上版本将支持python插件的python2.7和3.x版本 采集器pl […]
火车采集器可以抓取http以及https请求中的内容,因此只要手机APP是这两种请求类型,那么其中的内容理论上 […]

火车采集器V9.7之自动分类功能的使用方法教程 此功能是针对用户需求为:采集内容包含某个字符即将该字段的所有内 […]

默认采集器php并不是完整的安装环境,在确定php无语法错误,但调试时有的函数显示未定义 这有可能是因为php […]

该插件会利用google的在线翻译功能,将各种语言进行翻译。需要注意的是,使用该插件的翻译后采集速度将会受到一 […]

火车采集器V9.7采集类似天猫,淘宝等https的网站,无法采集,需要使用Ssl3协议 采集类似天猫淘宝等ht […]

火车采集器V9本地更新设置为MYSQL时运行任务会出现插入数据到数据库 在V9版本本地变更mysql数据库时出 […]
using System; using System.Collections.Generic; using S […]
火车采集器8.6版本增加了程序自动更新cookie功能。当使用外部程序(火车浏览器或用户自行开发的工具),自动 […]
火车采集器V9.7之discuz论坛接口上传附件20个限制解决方法 这个是由于网站所在的环境限制的 修改以下参 […]

火车采集器V9.7之discuz论坛利用组合标签实现单个附件下载功能,下面讲解下 discuz论坛 如何利用组 […]
火车采集器支持php插件对数据进行处理。php插件的原理是通过调用命令行的php.exe,对数据进行处理。 v […]
开始–运行中 输入 cmd 进入界面 再输入 […]
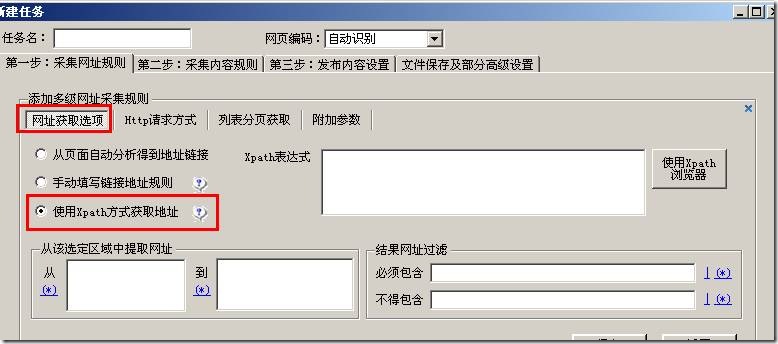
Xpath可视化提取功能旨在做到用户所见即所得,仅仅通过鼠标点击进行规则配置。但是此功能不适合大部分网站。 1 […]
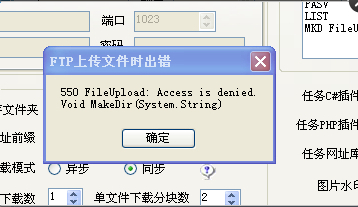
火车头采集器V9.7之FTP上传文件时出错550的解决方法 当提示如图错误的时候,请检查下 你的采集器 FTP […]
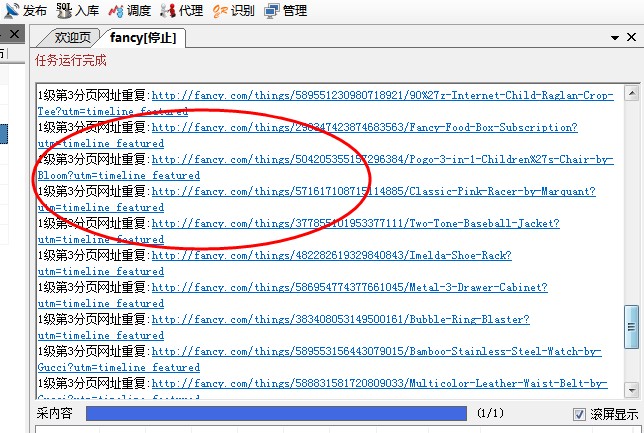
当提示如上图的时候,您可以通过清空网址和清空内容来重新运行采集。 另外,如果您不想排除网址重复 可以不勾选 这 […]
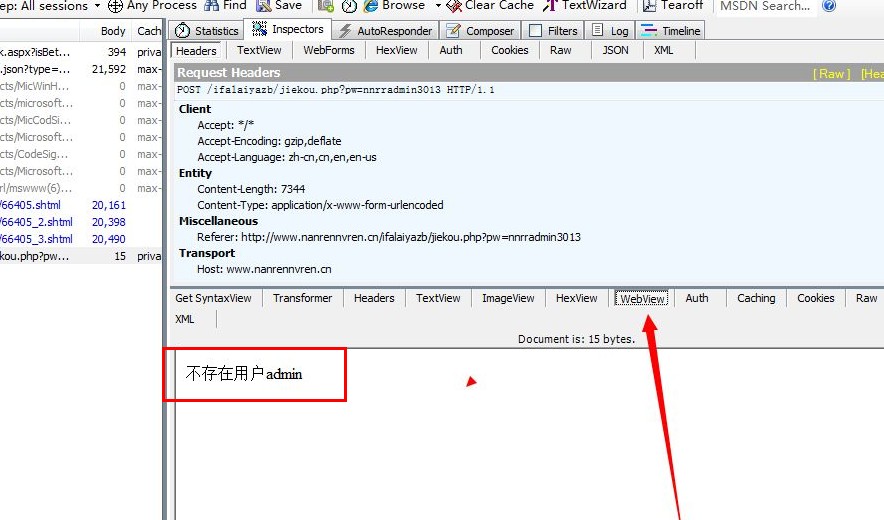
火车采集器之织梦接口发布提示用户名不存在的解决办法,有的时候,在使用织梦接口发布时,提示失败,抓包提示用户名某 […]
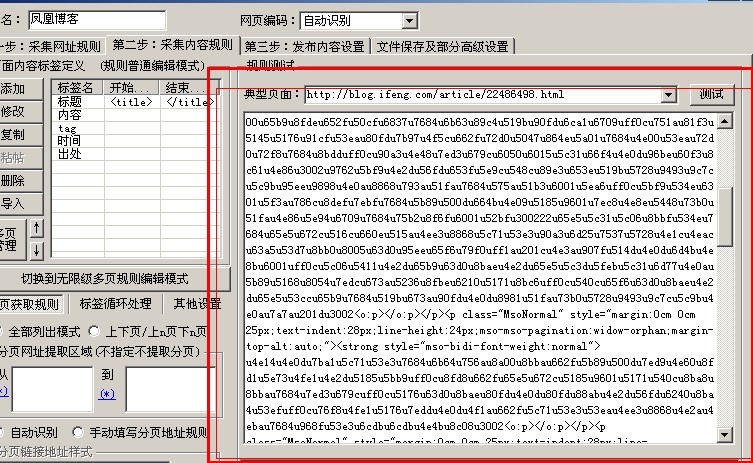
火车采集器里面的字符编码解码功能介绍,有时候采集的结果被转义了,那么如何获得我们要的结果呢?? 比如下图采集的 […]
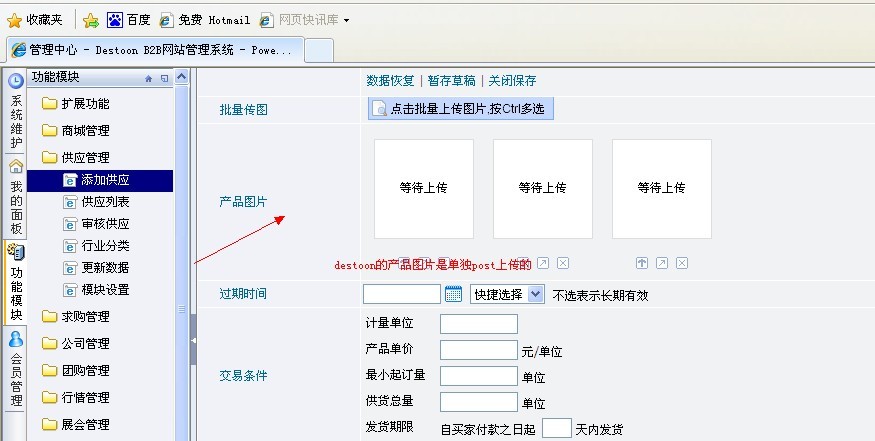
1、火车采集器之文件图片自动上传(post上传)简易教程,我们以destoon产品图片上传为例 2、选择一张本 […]

火车采集器采集淘宝天猫多页获取宝贝详细教程 以淘宝和天猫多页采集为例 淘宝,例如 http://item.ta […]
 中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
 人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
 英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
 英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
 英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
 国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
 英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
 英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
 多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
 英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
 英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
 英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
 英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
 全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
 英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00
英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00




