火车采集器V9智联招聘信息采集规则制作截图教程案例讲解 第一步:设置火车采集器起始网址 打开网址:http:/ […]

火车采集器V9智联招聘信息采集规则制作截图教程案例讲解 第一步:设置火车采集器起始网址 打开网址:http:/ […]

1、打开百度地图,以推拿为关键词采集一个城市的所有推拿店的信息,包括名称、地址、电话、坐标。 2、进入火车浏览 […]

今天给大家分享知乎网站问题及第一条回答内容的采集采集,通过搜索关键词采集相应的内容,本案例需要用到抓包工具来获 […]

火车采集器V9微信公众号文章采集规则制作教程分享 如何通过搜狗微信 http://weixin.sogou.c […]

很多网站的数据结构用到了Json格式,那么遇到这种格式的数据,用正常的采集规则是很难完美采集的,所以火车采集器 […]

今天主要讲解火车采集器采集东方财富网股票业绩预告信息规则教程,起始网址页即为内容页和标签循环采集功能,其他略过 […]

火车采集器采集住哪儿网酒店信息采集规则制作教程以北京地区酒店信息为例,入口页面:http://www.zhun […]
火车采集器V9安居客小区规则分享.rar (45.07 KB, 下载次数: 238)&n […]
火车采集器可以抓取http以及https请求中的内容,因此只要手机APP是这两种请求类型,那么其中 […]
<数字匹配> [1-9][0-9]{5,9} 匹配6到10位QQ号码 [1-9]表示第一位不能为0 […]

出现这种问题一般是由于系统的原因,下面介绍针对这种情况的解决方法: 一.由于IE未启动服务,以及.net版本不 […]

火车采集器V9.7多网站站群式发布,指选择多个发布配置时,同一条数据不会重复发布至一个网站中: 发布条件:假设 […]

sqlite中设置自增ID后,自增ID已经记录,就算清空已经采集的内容,再次采集时,自增ID也是从上一次的ID […]

如何解决火车采集器本地保存word文件时图片不显显示的问题 采集文章信息保存word想要有显示图片: 实现的方 […]

Web发布中内容发布之前的版本一直是粘贴发布中抓包的数据,然后软件自动分析表单名与表单值,但是对于一些特殊要求 […]

火车浏览器6.7版本安装后,运行提示,如下图: 解决方法是:需要安装一部分vc++组件,下载安装即可。 在安装 […]

PHPcms发布模块中 如何获取到全局变量 打开自己的phpcms后台的网站,如图 网址链接后缀hash= 即 […]

https类型网址,因为https协议中规定,https类型的网址是加密网址,采用的是长连接请求方式,所以在使 […]

“火车伪原创插件.dll” 文件放到Plugins目录下。 “火车伪原创插 […]

火车采集器代理IP设置方式目前分为两种: (1)将代理IP放在文本中,然后手动导入文本中IP。然后 […]

火车采集器V9.7的mysql入库存储过程实现功能教程 对于会更新数据的网站,如果可以通过一个字段判断该网页数 […]

火车采集器V9.7入库模块存储过程使用教程,当有类似下列应用场景: 将甲同学的姓名插入useinfo表,另甲同 […]

火车采集器错误该字符串未被识别为有效的DateTime的解决方法 采集器运行规则采集的时候出现以下错误 解决方 […]

火车采集器V9.7用cmd命令控制采集器运行任务规则或分组之后关闭 在火车采集器安装目录中,按shift键再右 […]

采集器9.4.3.0619新增采集预警功能,如下图 该功能是:当采集完成后,如果采集结果符合预设条件时,向指定 […]

很多朋友在用火车采集器的时候,希望能够定时自动采集自动发布,尤其是需要网站更新内容的,人没办法24小时守在电脑 […]
火车采集器V9.7版菜单栏工具功能之数据转换介绍 我们的火车采集器默认是Sqlite数据库,是软件自带无须安装 […]

带你认识了解火车采集器V9版菜单栏工具功能之运行统计 如上图,通过这个功能可以查看相应时间,所有任务的运行统计 […]

火车采集器V9版工具功能选项设置使用教程,带你认识了解火车采集器V9版菜单栏工具功能之选项设置 选项设置分为全 […]
火车采集器V9.7已采数据批量内容替换功能介绍,数据采集完了发现某个数据处理没设置或者设置的不对,需要重新设置 […]

火车采集器V9.7工具功能之同义词替换使用教程 先说说功能,其实就是自动替换数据中指定的词,比如将采集的A自动 […]
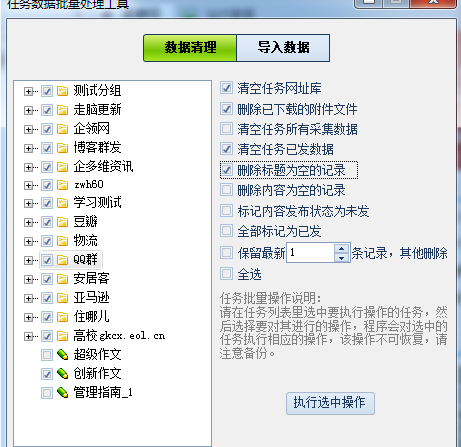
带你认识了解火车采集器V9版菜单栏工具功能之任务批量处理 火车采集器V9在菜单中有个工具栏,我们的很多用户在实 […]

火车采集器v9.7工具篇之任务批量编辑使用教程 我们在制作火车采集规则的时候,有时候会遇到很多规则有相似的参数 […]
 中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
 英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
 人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
 英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
 英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
 国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
 英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
 英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
 多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
 英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
 英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
 英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
 英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
 全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
 英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00
英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00




