火车头采集器DedeCMS5.6免登陆文章发布接口使用说明 一、火车头采集器DedeCMS5.6免登陆文章发布 […]

火车头采集器DedeCMS5.6免登陆文章发布接口使用说明 一、火车头采集器DedeCMS5.6免登陆文章发布 […]

有的时候 我们发现在浏览器里能看到的内容, 或者某个浏览器能看到 比如火狐能看到但是ie看不到 再或者 要把浏 […]

火车采集器采集规则如何导入导出,发布模块导入导出,分组导入导出说明规则的操作: 火车采集器采集规则导入规则的操 […]

1.首先打开火车采集器的自动运行设置工具!在采集器的菜单栏>>高级>>任务计划管理器 […]

1.火车采集器V7版本二级随机代理的使用教程,先打开二级随机代理工具,添加好代理的IP地址,然后验证一下是否可 […]

火车采集器发布模块如何设置ubb设置发布图片教程 ubb发布隐藏太深了,令很多位用户困解,本人也是找了半天。 […]

火车采集器的PHP插件和2010的插件是一样的。还是只处理列表页,内容页,多页的网页源代码,保存时的标签。 火 […]

正则匹配:^(?<content>[\s\S]*?)$

我们在使用火车采集器采集的结果被转义了,那么如何获得我们要的结果呢? 比如下图采集的结果中文都被转义成特殊的字 […]

fiddler使用实例之采集新浪滚动新闻 这个教程讲解下如何用fddler 找到页面的真是地址次教程属于高级、 […]

1、打开百度地图,以推拿为关键词采集一个城市的所有推拿店的信息,包括名称、地址、电话、坐标。 2、进入火车浏览 […]

今天给大家分享知乎网站问题及第一条回答内容的采集采集,通过搜索关键词采集相应的内容,本案例需要用到抓包工具来获 […]

火车采集器V9微信公众号文章采集规则制作教程分享 如何通过搜狗微信 http://weixin.sogou.c […]

今天主要讲解火车采集器采集东方财富网股票业绩预告信息规则教程,起始网址页即为内容页和标签循环采集功能,其他略过 […]

火车采集器采集住哪儿网酒店信息采集规则制作教程以北京地区酒店信息为例,入口页面:http://www.zhun […]
火车采集器V9安居客小区规则分享.rar (45.07 KB, 下载次数: 238)&n […]
<数字匹配> [1-9][0-9]{5,9} 匹配6到10位QQ号码 [1-9]表示第一位不能为0 […]

出现这种问题一般是由于系统的原因,下面介绍针对这种情况的解决方法: 一.由于IE未启动服务,以及.net版本不 […]

火车采集器V9.7多网站站群式发布,指选择多个发布配置时,同一条数据不会重复发布至一个网站中: 发布条件:假设 […]

火车浏览器6.7版本安装后,运行提示,如下图: 解决方法是:需要安装一部分vc++组件,下载安装即可。 在安装 […]

https类型网址,因为https协议中规定,https类型的网址是加密网址,采用的是长连接请求方式,所以在使 […]

“火车伪原创插件.dll” 文件放到Plugins目录下。 “火车伪原创插 […]

火车采集器V9.7的mysql入库存储过程实现功能教程 对于会更新数据的网站,如果可以通过一个字段判断该网页数 […]

火车采集器V9.7入库模块存储过程使用教程,当有类似下列应用场景: 将甲同学的姓名插入useinfo表,另甲同 […]

火车采集器V9.7用cmd命令控制采集器运行任务规则或分组之后关闭 在火车采集器安装目录中,按shift键再右 […]

很多朋友在用火车采集器的时候,希望能够定时自动采集自动发布,尤其是需要网站更新内容的,人没办法24小时守在电脑 […]
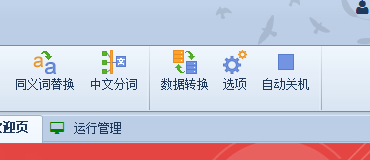
火车采集器V9.7版菜单栏工具功能之数据转换介绍 我们的火车采集器默认是Sqlite数据库,是软件自带无须安装 […]

带你认识了解火车采集器V9版菜单栏工具功能之运行统计 如上图,通过这个功能可以查看相应时间,所有任务的运行统计 […]

火车采集器V9版工具功能选项设置使用教程,带你认识了解火车采集器V9版菜单栏工具功能之选项设置 选项设置分为全 […]
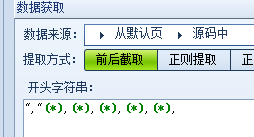
给大家分享财富网股票业绩预告信息采集规则。今天的规则相对比较简单,但简单中又有技巧, 比如看到这个图的规则,会 […]

[参数]在火车采集器中是一个标记标签,用来匹配某些待提取的信息。这里和(*)区分开来,(*)是通配符号,用来代 […]
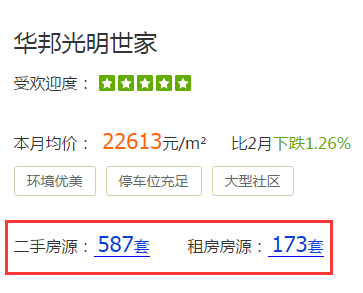
我们在采集网页信息过程中经常遇到信息不在同一个页面,那就要使用多页功能,今天在这里以采集安居客小区信息为例讲解 […]
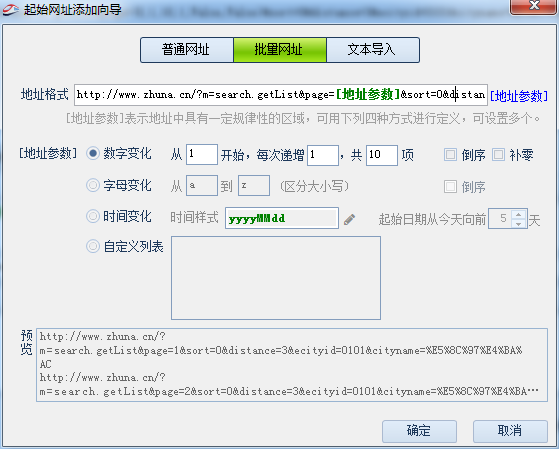
今天为大家讲解网址拼接,我们经常在采集的时候,发现源码中并没有完全的网址或完全的网站不好制定规则,那就可以使用 […]
 中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
中文wp网站下载资源站 带数据 主题模板 虚拟文档 带会员功能 知识付费源码 可选采集器
¥99.00
 英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
英文高清桌布壁纸 桌面图片 整站模板导入成站 图片壁纸WordPress网站主题 带图片内容采集软件
¥49.00
 人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
人工智能根据标题生成原创内容,火车头采集器AI伪原创插件,GPT AI生成多语言内容
¥300.00
 英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
英文Lead联盟交友约会平台 集成会员支付聊天功能的Dateing网站wp模板
¥299.00
 英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
英文博客模板 运营比特新闻杂志广告 币圈门户网站WP主题 附送自动电脑采集软件
¥59.00
 国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
国外联盟平台 英文联盟Lead广告加盟 交友约会网站模板 情感文章采集发布
¥89.00
 英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
英文在线独立商店模板 蓝色服装鞋帽装饰WordPress网上会员商城源码woocommerce主题模板 可选采集功能
¥69.00
 英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
英文联盟模板 健身健康美体运动WordPress整站数据 带采集器软件 批量采集内容
¥49.00
 多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
多平台自适应 全新英文游戏网站主题 DIV+CSS游戏整站模板 带采集软件自动采集
¥49.00
 英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
英文HTML静态网页模板 约会社交网站模板 成品网站 上传就成站页面模板
¥19.90
 英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
英文联盟网站源代码 极客科技网站WordPress主题模板整站数据 挂广告 内容自动采集发布
¥49.00
 英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
英文联盟整站模板 influencer社交欧美娱乐名人WordPresss新闻网站 图片网站
¥49.00
 英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
英文整站模板 游戏新闻门户社交WordPress网站主题 带内容采集器
¥49.00
 全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
全自动无人值守 英文网站 世界新闻资讯WordPress主题整站数据 带机器人采集
¥86.00
 英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00
英文世界财经新闻整站模板 国外广告联盟WordPress主题 附文章采集器
¥49.00




