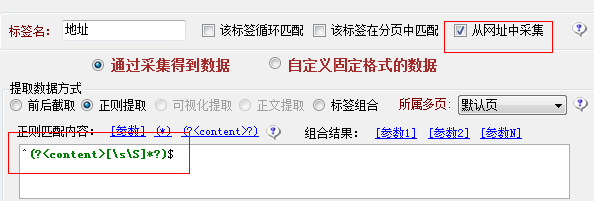
有很多用户不知道火车采集器标签循环匹配及标签在分页中匹配这两个功能的使用,下面就以百度搜索列表采集为例,采集地址http://www.baidu.com/s?wd=%E9%87 … =32&inputT=3893,直接将这个列表页地址作为实际内容页采集,
查看源文件,得到每条记录标题所在的html代码格式是所以在采集标题时规则设置如下
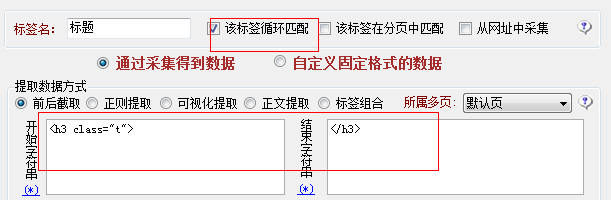
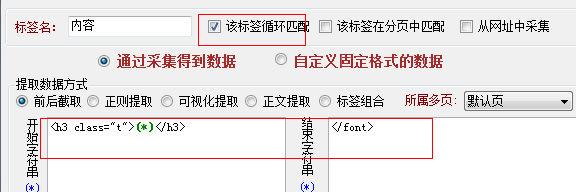
打开火车采集器勾选截图中的该标签在循环中匹配,这样就可以循环采集到每条记录的标签,采集内容标签规则设置如下,一样需要设置循环匹配,
这个列表的分页需要在第二步分页设置中截取到分页连接地址,
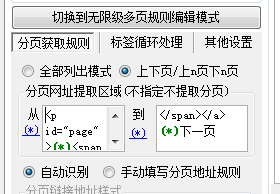
火车采集器分页规则设置好后,勾选每个标签里的该标签在分页中匹配选项,

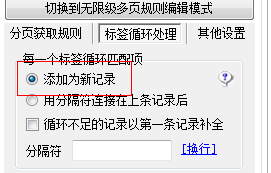
如果需要将采集的数据一条条保存,需要选择添加新纪录方式,
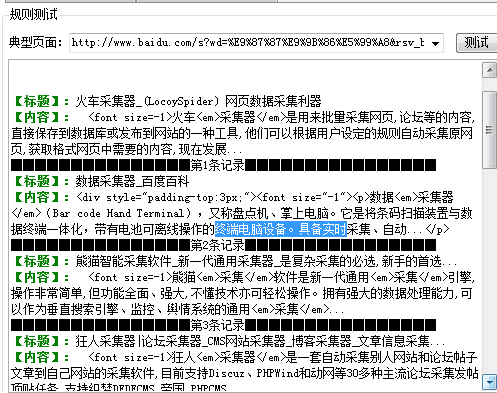
最后测试效果如下:
如果需要获取内容页地址或者内容地址中部分参数这就需要使用从网址中采集功能,然后使用正则采集,