火车采集器采集住哪儿网酒店信息采集规则制作教程以北京地区酒店信息为例,入口页面:http://www.zhuna.cn/hotellist/e0101/
通过页面点击发现这并不是真实的数据列表页,需要通过抓包软件来抓包,找出真实列表网址(抓包之前说过,今天这里不再细说),通过抓包获得真实网址为:http://www.zhuna.cn/?m=search.getList&page=1&sort=0&distance=3&ecityid=0101&cityname=%E5%8C%97%E4%BA%AC
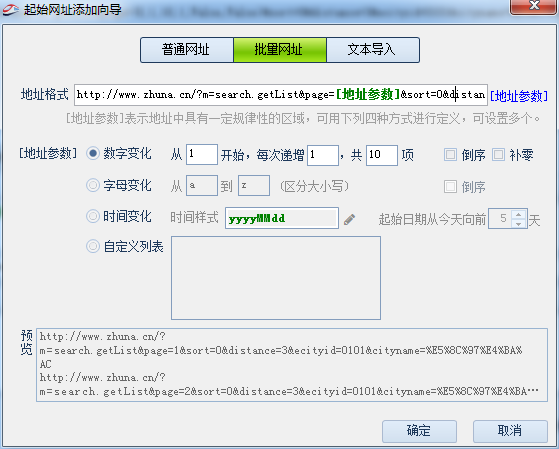
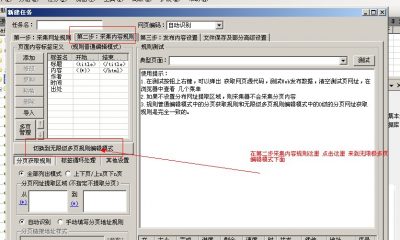
在火车采集器网址中的page=1为列表页分页参数,通过分页规则,采集列表网址,如图:
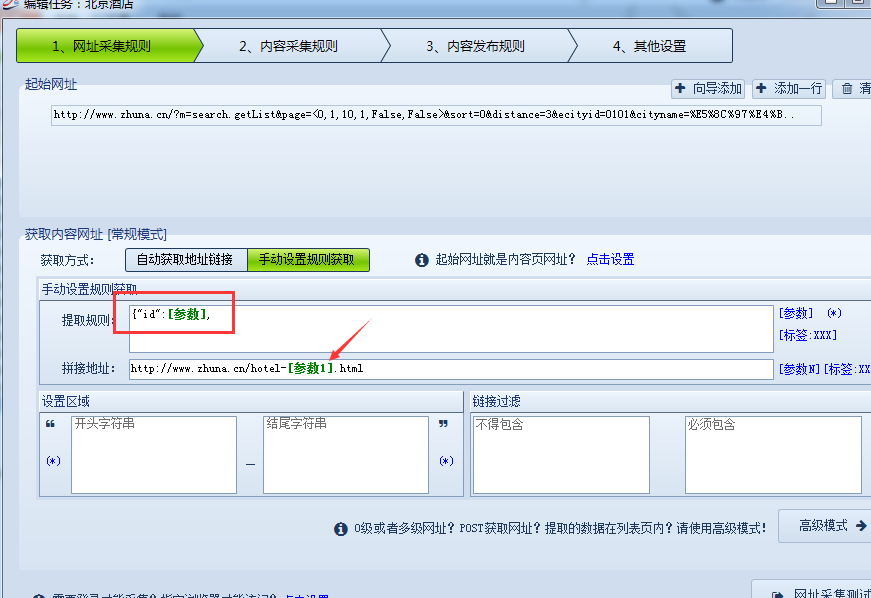
下一步获取内容页网址,通过源码分析,发现源码中并没有网址,但可以看到一个ID值,如图:

通过页面点击内容页发现内容网址为http://www.zhuna.cn/hotel-5396.html 网址中的数字很可能就是这个ID值,将源码中的ID值替换到这个网址中,发现就是酒店详细内容页,这样我们只要采集这个ID值即可。这个获取规则也很简单,以{"id":开头,以 , 结尾,就可以获取到ID值,但光有ID值不行,这个时候我们要拼接出完整的内容网址,那这样拼接http://www.zhuna.cn/hotel-[参数1].html即可,如图:
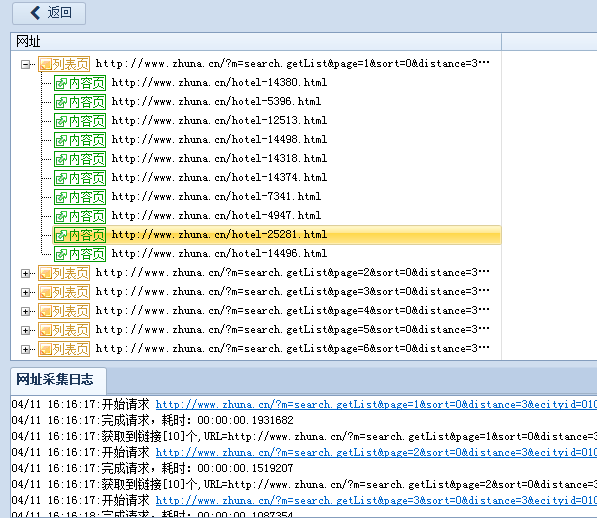
通过火车采集器网址测试,可以顺利采集到内容网址
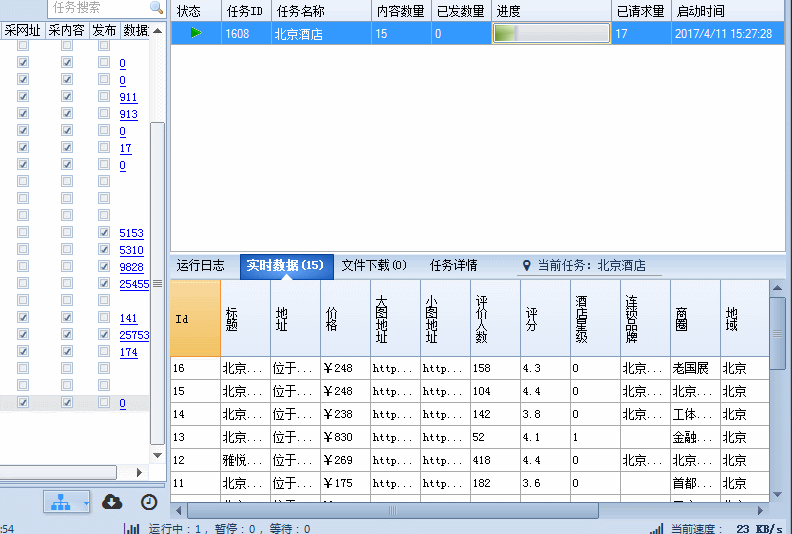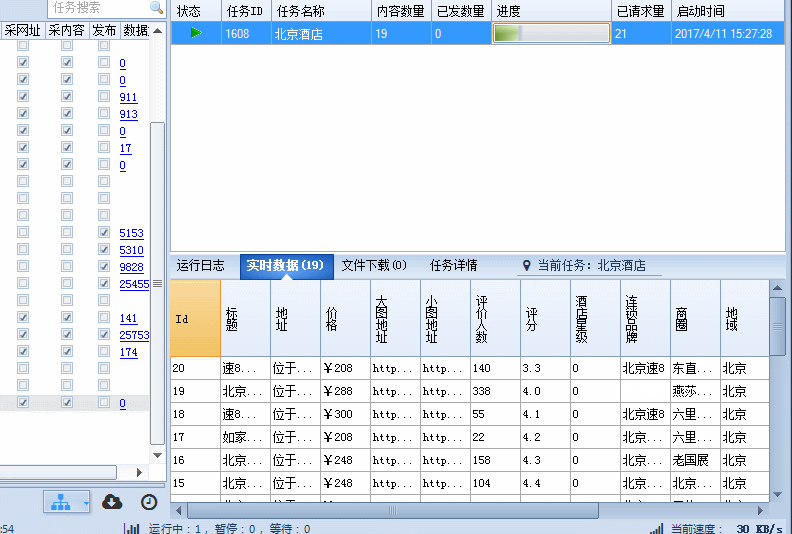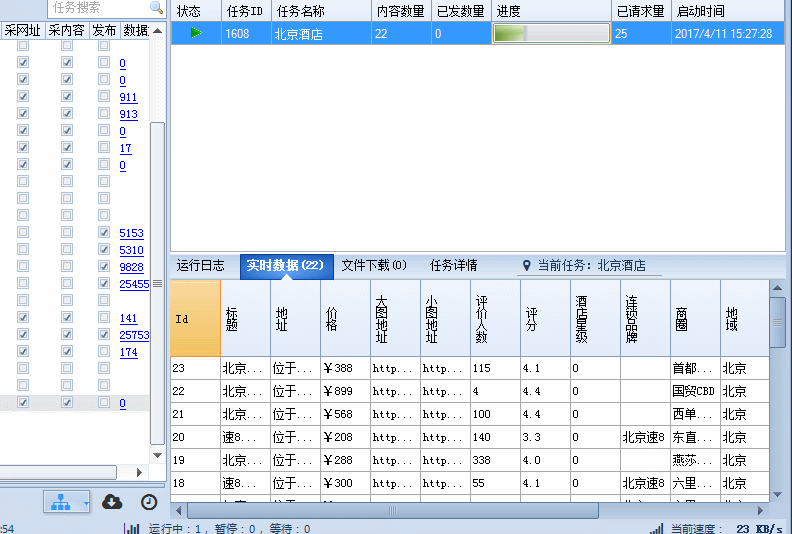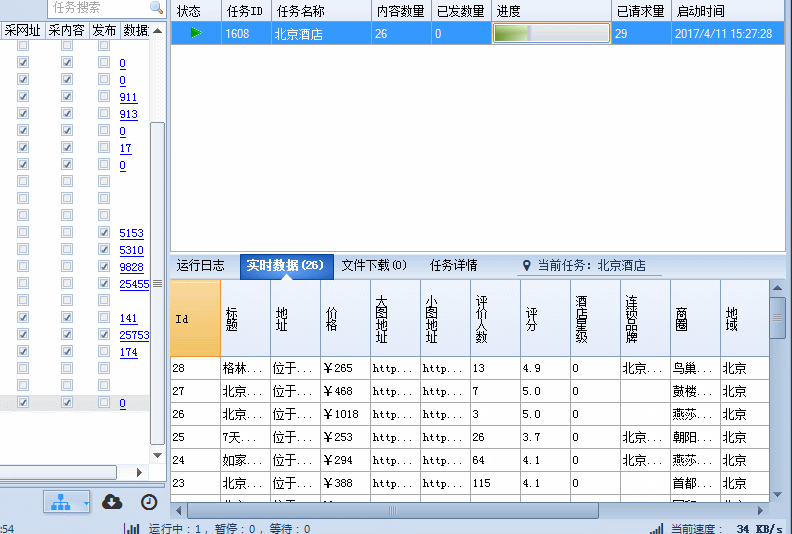
酒店的基本信息在内容页源码中都有,规则也比较简单,在这里就略过,最后来张采集动态图
























RSS