案例网站:http://www.mornsun.cn/html/selection.html
采集内容:如下图

网站分析:
通过点击页面分页,发现网址并无变化,说明这不是真实的数据列表地址,那么就需要通过抓包软件Fiddler来抓包分析了。
(关于fiddler的使用教程:http://faq.locoy.com/search.html?keyword=fiddler)
打开抓包软件,点击分页
![]()
通过抓包软件获取到的信息我们可以分析得出,该页需要使用POST功能,才能获取到数据。如图:

图中1处是找到对应的数据存在的网址,不确定的话可以多试,一般做得多了一眼看就知道哪个,可以通过图上2处来确认是不是数据网址,能在2处看到需要的数据就是正确的了。
然后通过图中3位置来查看网址请求类型和cookie。我们可以看到应该网址是POST类型,图中4处就是要Post的参数值。接下来我们需要复制该Post网址:“http://www.mornsun.cn/index.php?c=selection&a=search”到采集器软件起始网址中,如图:
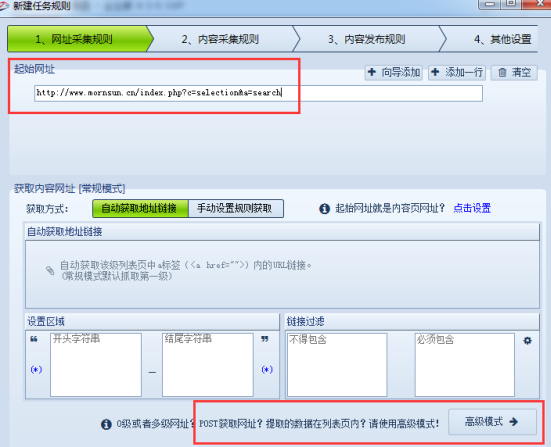
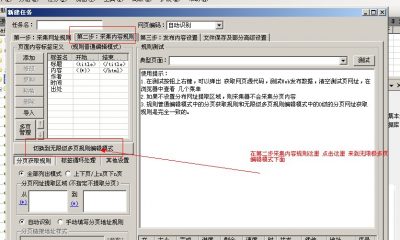
设置POST需要点击高级模式,然后我们添加一级列表,这里还是获取内容页网址规则,内容页的网址规则通过抓包获取,参照上面抓包的图中2位置,可以通过此源代码找出内容网址规则。

接下来是Post设置,上面讲到图中4处是post参数值,现在我们需要将那串参数值复制,也就是“page=2&keywords=&pid=2&Package=&OutputPower=&NoofOutput=&VoutVDC=&VinVDC=&IsolationVDC=” 复制到采集器中,我们需要将其中的分页参数2改为变量[分页],然后设置页码数,这样Post就设置好了,如下图:
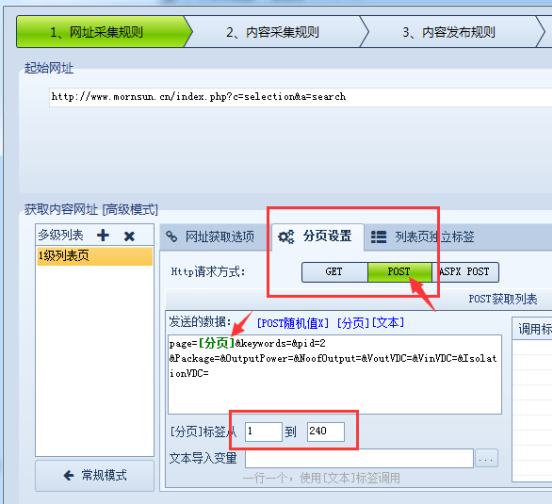
当然这只是一个最简单的一个post案例,复杂的会有更多的参数和变量,但是最基本的原理还是这样的,最主要是要学会抓包分析。有时候可能不知道哪个参数是分页数,可以多抓几个页面,将参数复制到记事本进行对比,一般面码的数字变化是很有规律的,通过对比找到规律就知道哪个参数是分页值了。
























RSS