火车采集器V9智联招聘信息采集规则制作截图教程案例讲解
第一步:设置火车采集器起始网址
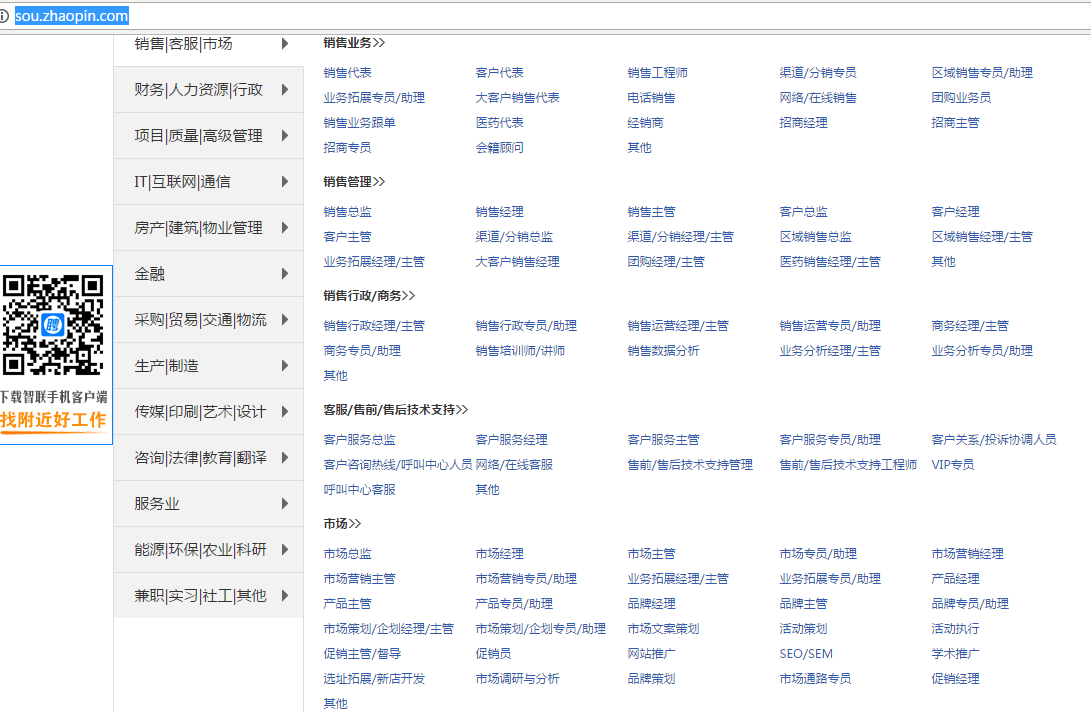
打开网址:http://sou.zhaopin.com/ 同时这也是火车采集器的入口网址,将此网址输入在火车采集器的起始网址中
打开网站我们可以看到,这上面都是招聘信息的职位类别,我们要采集到这些类别的链接,我们查看源码,如下图:

第二步:获取类别链接及类别名称
这里我们除了将类别网址链接获取到,同时将类别名称获取到,所以这里使用了列表页标签功能
通过源码找到获取链接的规则如下:
onclick="javascript(*)href="[参数]"(*)_blank"></a>
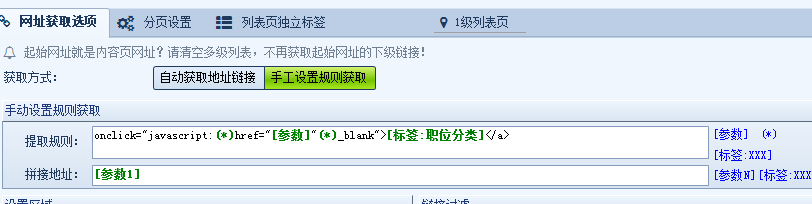
参照上图进行设置,这样类别链接获取就设置好了,然后我们点开任意类别页面,进入招聘信息列表页,如下图:
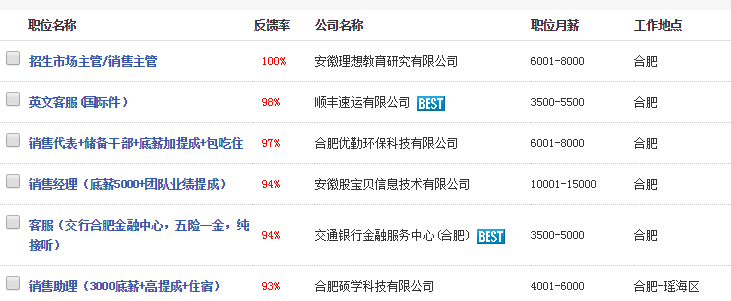
第三步:内容页网址获取设置
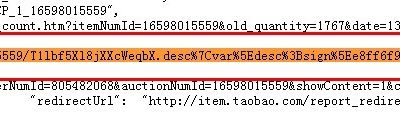
我们要获取列表页上的招聘信息网址,也就是内容页网址,同样我们查询源码,分析规则,如下图:

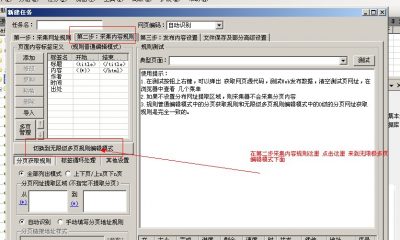
这里已经是属于第二级网址,我们将网址设置切换为高级模式,然后添加2级列表页,然后设置如下:
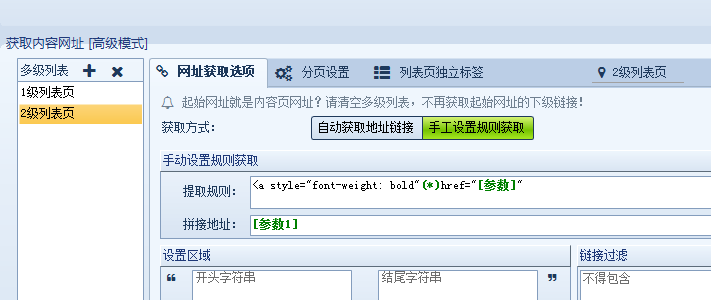
这样内容页的网址链接采集就设置好了,但我们发现列表页下方还有分页,所以我们还要设置分页
第四步:设置分页
获取如下图中的分页
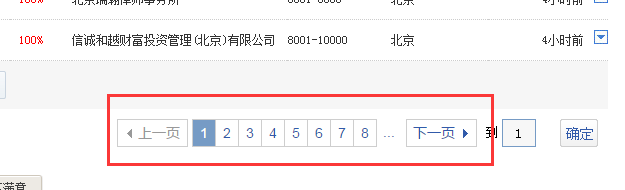
同样是查询源码寻找规则,

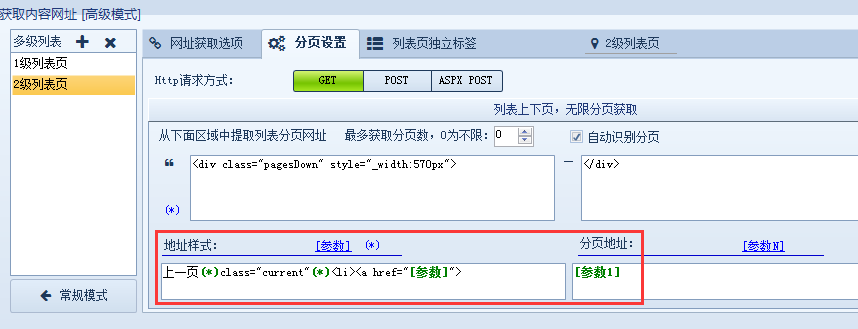
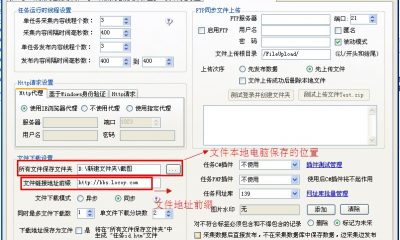
然后火车采集器,选择分页设置,设置好分页范围,以及分页链接的规则,上一页(*)class="current"(*)参照下图:
设置好后,我们进行网址测试,如下图:
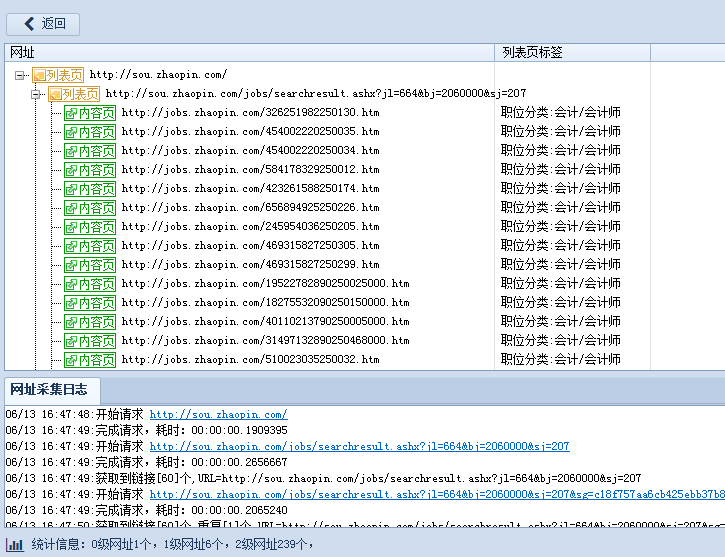
这样所有网址采集就设置好了
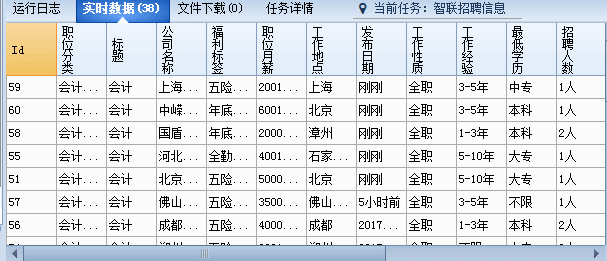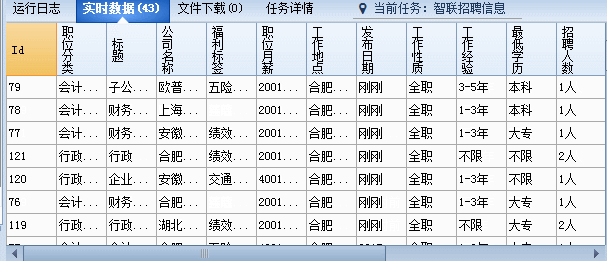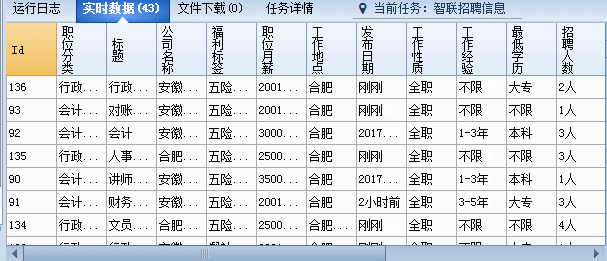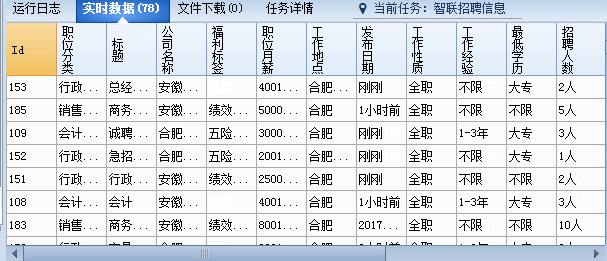
第五步:招聘信息内容采集设置
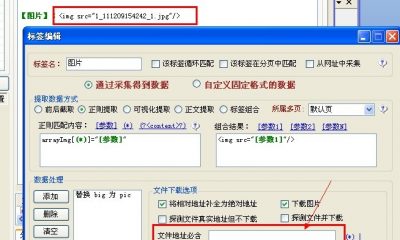
我们打开任意招聘信息内容页,采集页面上的信息,如下图:
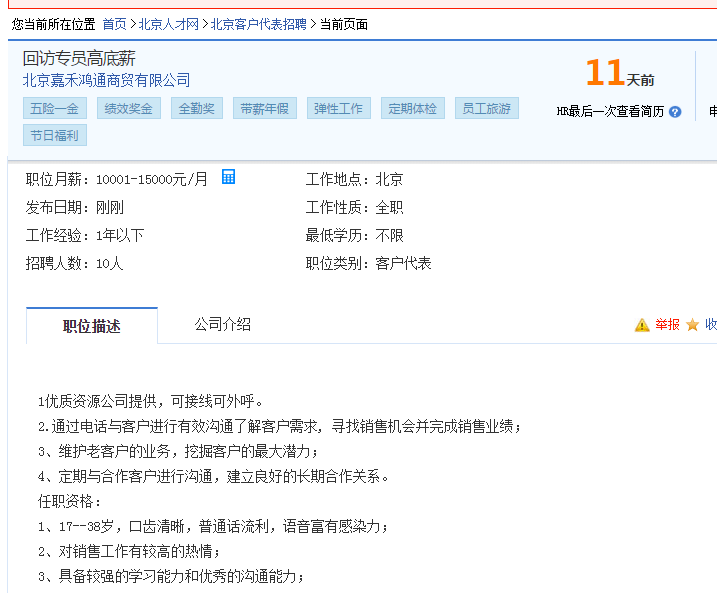
采集器切换到内容采集规则,内容的采集就不一个一个讲,这里没有什么难点,还是查看网页源码,分析规则进行设置即可,大家可自行查看每个字段的规则设置,来学习规则原理,参照下图:
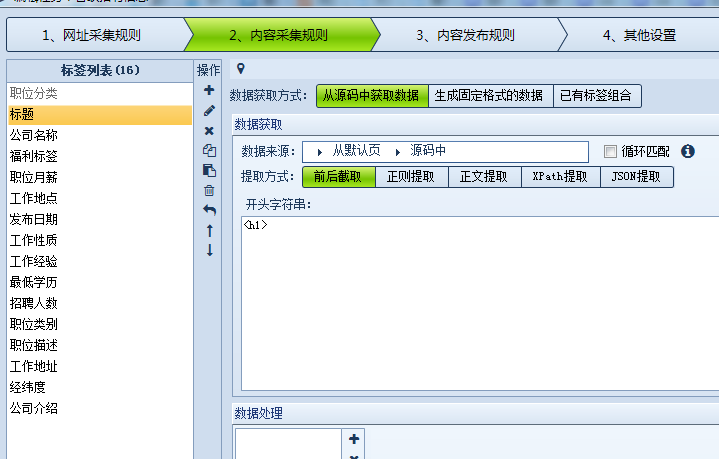
第六步:测试火车采集规则
所有的内容字段采集设置好,我们进行测试,可以多测试几个页面,以确保规则能够没问题。
当然我们在设置每个字段的时候也可以进行测试来检验规则。
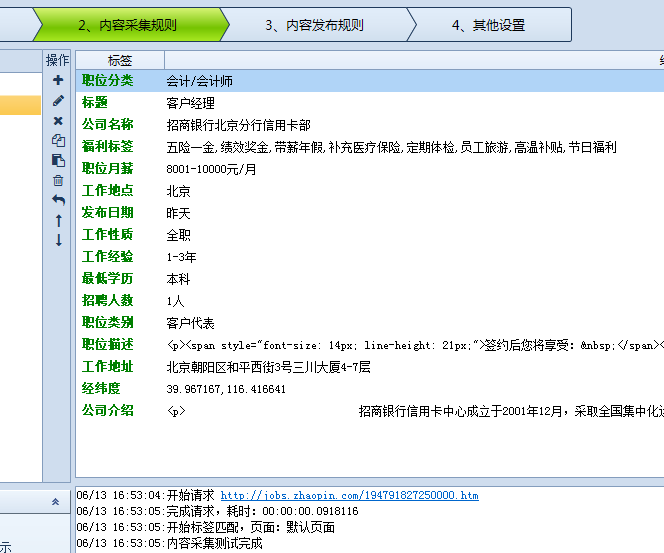
确保没问题后就可以进行采集了,看这速度,是不是很爽爽!!赶紧去试试吧!





















RSS